The Problem I Wanted to Solve #
Let’s face it attention spans are short. In the age of TikTok, ChatGPT, and “TL;DR,” people want instant, relevant answers without wading through walls of text or scrubbing through 30-minute videos (which they’ll probably watch at 2x speed anyway).
Whether reading a blog, seeking support, or navigating a product, attention is the new currency. But myself and most users are bankrupt. So I wanted to build something that respected people’s time: something that gets straight to the point and delivers value fast, with no fluff.
What Is RAG? #
Retrieval-Augmented Generation (RAG) is an AI pattern that combines two powerful components: a language model (like OpenAI’s GPT-4o-mini) and a retrieval system. Instead of relying solely on the model’s training data, RAG actively fetches relevant documents from an external source like a blog, knowledge base, or docset and uses them to generate grounded responses.
This makes answers more accurate, contextual, and up-to-date while reducing hallucinations (when the AI just makes stuff up). RAG is especially useful for support bots, internal tools, or anything that needs reliable, source-backed answers.
The Role of FAISS #
FAISS (Facebook AI Similarity Search) is an open-source library from Meta designed for high-speed similarity search across vector data. In RAG systems, FAISS is the retrieval engine it searches through vectorised documents to find the ones most relevant to a user’s query.
Here’s how it works in my setup:
- I load all the markdown files from my
./contentfolder using a directory loader. - Each file is split into overlapping chunks using a character-based splitter to preserve context.
- Those chunks are converted into vectors using OpenAI’s embedding model.
- I use FAISS to index and store these vectors for fast searching in two files
docstore.jsonandfaiss.index. These are manually generated via a function ingenerateVectorStore.mjsand committed to the git repo.
When someone asks a question, the system turns that query into a vector and compares it against the stored vectors to find the top matches. These are passed into the language model via LangChain to generate a tailored response.
Building the Chatbot UI #
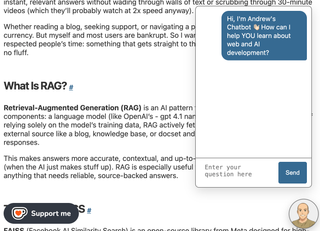
To keep things lightweight, I built the chatbot in plain vanilla JavaScript and CSS—no frameworks, no heavy dependencies.
- The script loads only when the user clicks the anime version of me toggle button, keeping page performance fast.
- It prevents multiple initialisations and uses minimal DOM manipulation for smooth async interactions.
- Animations for showing and hiding the chat are done with CSS, and messages are handled with a single
fetch()call.
This lean approach makes the chatbot snappy, efficient, and perfect for a static Eleventy site.
How It Works (Under the Hood) #
When a user submits a question through the UI, it sends a POST request to a Netlify Function:
/.netlify/functions/chatragThe request payload looks like this:
{
"question": "What is RAG?"
}On the backend, the chatrag.mjs Netlify Function handles everything:
- Sanitises input (length check, special character stripping).
- Loads the FAISS vector store (
./vector_store) and retrieves relevant chunks. - Sends the question and context to OpenAI via LangChain.
- Returns a structured JSON response with the answer.
The frontend parses this response and appends the answer in the chat window.
Deployment Details #
The site is deployed to Netlify with:
- The static site generator via Eleventy.
- It has a Serverless backend handled by Netlify Functions (Azure Functions / AWS Lambda equivalent).
The chatbot uses the chatrag function, which accesses the prebuilt vector store files (docstore.json and faiss.index).
To make the vector store files available to the function I have to add the included_files config to the netlify.toml file. This ensures the vector data is bundled with the function when I deploy the functions (via Netlify CLI deploy command).
[functions."chatrag"]
included_files = ["vector_store/docstore.json", "vector_store/faiss.index"]Everything is file-based, serverless, and optimised for performance and is virtually free to host due to it being static files and serverless. There is no expensive database to host or node.js server waiting constantly to serve the backend.
You can see the chatbot in action on my blog at andrewford.co.nz by clicking the anime version of me button in the bottom right corner on any page of the website.
What’s Next #
Now that the core system is up and running with a lightweight chatbot, FAISS-based vector search, and OpenAI powered answers here are a few upgrades I’m considering:
- Add source links to answers, showing the origin of each response to build trust and transparency.
- Enable streaming responses (word-by-word or sentence-by-sentence) using Netlify Edge Functions, making the chatbot feel faster and more natural.
- Suggest follow-up questions to keep users engaged and help them explore topics further.
- Go multilingual, either through automatic translation or by supporting input in multiple languages.
Each of these enhancements is modular, so I can add them incrementally at my own leisure while keeping the chatbot, lightweight, simple, and easy to maintain.
Source code is available on GitHub